
随着人工智能技术的飞速发展,选择适合的大模型对开发者至关重要。2025年5月,谷歌在 I/O 大会上推出的 Gemini 2.5 Flash Preview (05-20) 以其高效低成本的特性受到关注,在 LMArena.ai 排行榜中位列第二,仅次于 Gemini 2.5 Pro Preview。同期,xAI 的 Grok 3和 Anthropic 的 Claude 4 Sonnet(2025年5月22-23日发布)也以卓越性能备受瞩目。我们利用 POLOAPI 平台的高效模型调用功能,对这三款模型进行了全面测试,涵盖逻辑推理、多模态处理和代码生成等场景,旨在为开发者提供客观的性能参考。本文通过全新设计的测试任务,结合官方定价信息,深入分析三款模型的表现,并探讨其在实际场景中的应用潜力。
模型定价概览(单位:美元/百万 token)
| 模型 | 输入价格 | 输出价格 |
|---|---|---|
| Gemini 2.5 Flash Preview (05-20) | $0.15 | $3.50 |
| Grok 3 Reasoning | $3.00 | $15.00 |
| Claude 4 Sonnet | $3.00 | $15.00 |
性能评测与分析
1. 逻辑推理能力
逻辑推理能力是大模型处理复杂问题的核心。我们设计了以下任务,测试模型的语义理解和推理能力。
1. 逻辑推理
提示词:如果今天我有5本书,昨天借出了3本,现在我手上有几本书?
题目解析:此题考察模型对时间语义和当前状态的理解。提示词明确指出“今天我有5本书”,因此昨天的借书行为不影响当前数量,正确答案为 5本书。这是一个看似简单但容易因过度推理而出错的问题。
-
Gemini 2.5 Flash:正确回答 5 本书,简洁指出当前状态优先于历史行为。

-
Grok 3:Grok 3 Reasoning 模型在回答“今天有5本书,昨天借出3本,现在有几本”时出现了逻辑错误,它错误地将“今天有5本书”理解为初始数量,并从中减去昨天借出的书本数,忽略了“今天有5本书”已明确当前状态。正确理解应是:不论昨天发生了什么,既然题目说“今天有5本”,那现在手上就有5本书。模型混淆了时间顺序和语义前提,导致推理失误。
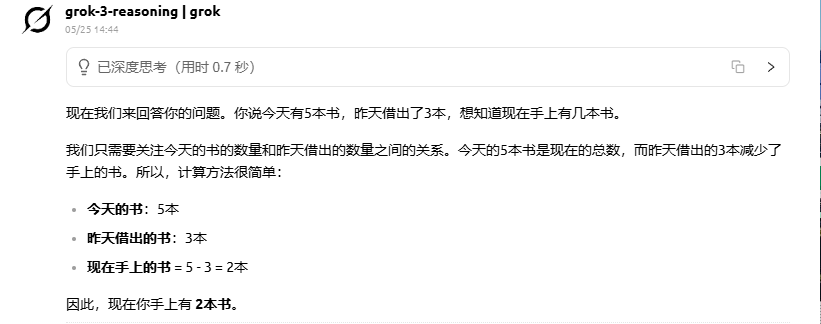
-
Claude 4 Sonnet:Claude Sonnet 4 的回答明确以“今天有5本书”为当前事实,同时指出“昨天借出3本”可能引起理解混淆,并提供了不同解释的可能性,表现出良好的语言歧义识别与澄清能力,是更稳健、贴近人类思维的答复方式。
-

分析:在这道考察时间语义理解的逻辑推理题中,各大模型表现差异明显:Gemini 2.5 Flash直接给出正确答案“5本书”,明确以当前状态为依据,展现出高效准确的推理能力;Grok 3 Reasoning则犯了典型的时间理解错误,把“今天有5本书”误当作初始值,并错误地从中减去“昨天借出3本”,未能区分历史行为与当前状态;相比之下,Claude 4 Sonnet不仅准确理解题意,还进一步指出题目中“昨天借出”的潜在歧义,展现出更强的语言敏感性和人类般的澄清意识,是三个中最稳健的模型。
2. 数学问题
提示词:使用数字 2、3、7、8 和四则运算(加、减、乘、除及括号),计算得到 36,每个数字使用且仅使用一次。
题目解析:这是一个经典的24点式问题变种,考察模型的数学推理和逆向思维能力,需要灵活运用分数和括号以达到目标值 36。
-
🧠 Grok-3-Reasoning
-


回答特点:
-
清晰的解题过程:模型详细描述了解题的思路,强调了乘法和加法在接近目标数值中的作用。
-
准确的表达式:最终给出正确的表达式
(7 + 8 + 3) × 2 = 36,并逐步验证了计算过程。 -
结构化的呈现:回答分为“解题过程”、“表达式”、“验证”和“结论”四个部分,逻辑清晰,便于理解。
评价: Grok-3-Reasoning 展现了强大的逻辑推理能力和清晰的表达,能够有效地引导用户理解解题过程。
⚡ Gemini-2.5-Flash-Preview-05-20
-
-

回答特点:
-
简洁明了:直接给出解法步骤:
8 + 7 + 3 = 18,然后18 × 2 = 36,得出表达式2 × (8 + 7 + 3) = 36。 -
快速响应:回答迅速,适合需要快速获取答案的场景。
评价: Gemini-2.5-Flash-Preview-05-20 提供了快速且准确的答案,但缺乏详细的解题过程说明,适合对解题过程不感兴趣的用户。
🤖 Claude-Sonnet-4-20250514
-
-


回答特点:
-
多次尝试:模型尝试了多种组合方式,但多次出现重复使用数字或引入未提供的数字的情况。
-
缺乏有效的验证机制:在多次尝试中,未能有效地验证每次尝试的正确性,导致最终未能给出正确答案。
评价: Claude-Sonnet-4-20250514 展现了一定的探索能力,但在解题准确性和验证机制方面存在不足,未能成功解决问题。
-
3. 图片基础认知
提示词:这张图片出自哪部电影?请说出图中角色的名字。
(图片:来自《疯狂动物城》的兔子朱迪)
题目解析:此题测试模型的图像识别和文化知识能力,正确答案为《疯狂动物城》(Zootopia),角色名为 朱迪·霍普斯(Judy Hopps)。
-
Gemini 2.5 Flash:正确识别电影为《疯狂动物城》,角色名为朱迪·霍普斯,回答准确无误。

-
Grok 3:因不支持图像输入,无法处理此任务,回答失败。
- Claude 4 Sonnet:正确识别电影为《疯狂动物城》,角色名正确并且对这个角色进行详细的介绍。
-
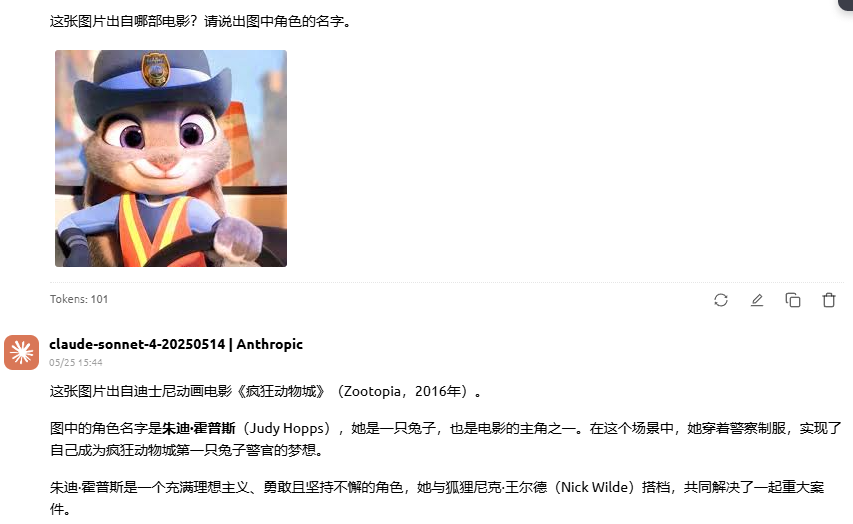 分析:在这道图像识别题中,模型能力差异显著:Gemini 2.5 Flash准确识别出图片来自电影《疯狂动物城》,角色是朱迪·霍普斯,展现了良好的图像与文化知识融合能力;Grok 3由于不支持图像输入,直接无法作答,表现受限于功能缺失;Claude 4 Sonnet不仅准确识别出电影与角色,还补充了角色背景信息,体现出更强的理解深度与语言表达能力,是三者中最全面的回答者。
分析:在这道图像识别题中,模型能力差异显著:Gemini 2.5 Flash准确识别出图片来自电影《疯狂动物城》,角色是朱迪·霍普斯,展现了良好的图像与文化知识融合能力;Grok 3由于不支持图像输入,直接无法作答,表现受限于功能缺失;Claude 4 Sonnet不仅准确识别出电影与角色,还补充了角色背景信息,体现出更强的理解深度与语言表达能力,是三者中最全面的回答者。
4. 视觉应用
提示词:在社交媒体界面上,我想点赞这个帖子,应该点击哪个按钮?请说出按钮的序号。

题目解析:此题考察模型的视觉交互能力,要求识别界面元素并理解功能,正确答案为 1号。
Grok-3-Reasoning:

回答特点:
逻辑清晰、推理完整,它通过构建一个典型的社交媒体界面作为假设,详细描述点赞、评论和分享按钮的位置及图标含义,并通过推理得出点赞按钮是第一个,体现出较强的解释能力和教学导向,适合需要理解背后逻辑或用于培训场景的用户。
Claude-Sonnet-4:
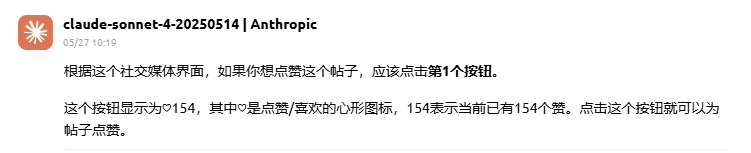
回答特点:
更加紧凑实用,直接指出第一个按钮是点赞按钮,并引用具体的界面元素“♡154”,不仅提供了结论,还增强了与实际 UI 的关联性,适合需要结合视觉界面快速操作的用户。
Gemini-2.5-Flash:

回答特点:
Gemini-2.5-Flash 的风格更加简洁直接,重点强调心形图标的语义代表“赞”或“喜欢”,省略了过多的上下文解释,适合熟悉图标含义、想快速获取答案的用户。
总结性分析:综上所述,Grok-3-Reasoning、Claude-Sonnet-4 和 Gemini-2.5-Flash 三个模型在面对相同问题时展现出了各自独特的回答风格和优势。Grok-3-Reasoning强调推理过程和逻辑结构,适合需要理解背景和原理的场景;Claude-Sonnet-4结合界面实际元素,强调实用性和上下文贴合,适用于操作型和界面识别类问题;而Gemini-2.5-Flash则以简洁明了为核心,快速给出结论,适合对结果有快速需求的用户。这种风格差异体现了当前大模型在智能问答中的多样性与互补性:不同模型在相同任务中不仅可以提供一致的答案,还能以多种表达方式服务于不同的用户需求,从而提高整体的人机交互体验。
5. 前端编程
提示词:请用前端代码制作一个简易贪吃蛇游戏,包含游戏说明和开始按钮,所有代码放在一起输出。
题目解析:此题测试模型的代码生成能力,评估代码的功能完整性、界面美观性和可玩性。理想的贪吃蛇游戏应包含动态食物生成、碰撞检测和简单的用户界面。
Gemini 2.5 Flash:
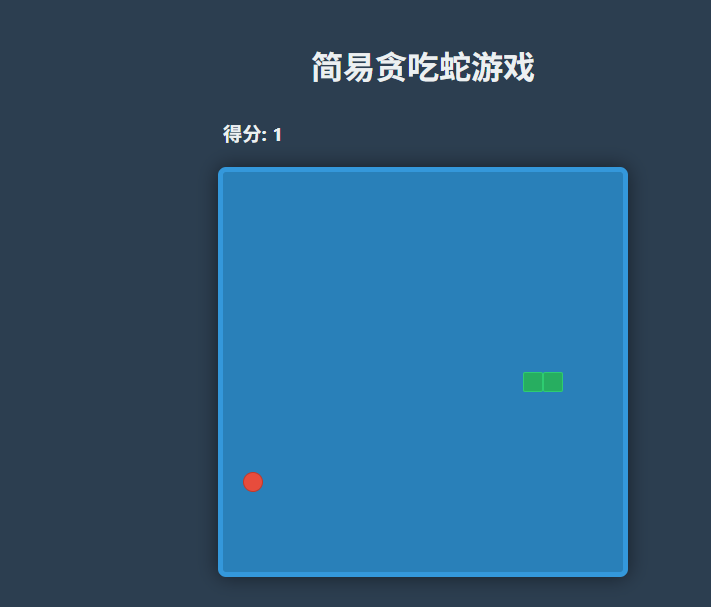
回答特点:
生成基于 HTML5 Canvas 的贪吃蛇游戏,代码功能完整,包含动态食物生成和碰撞检测,界面简洁美观,整体表现优秀。
Grok 3:
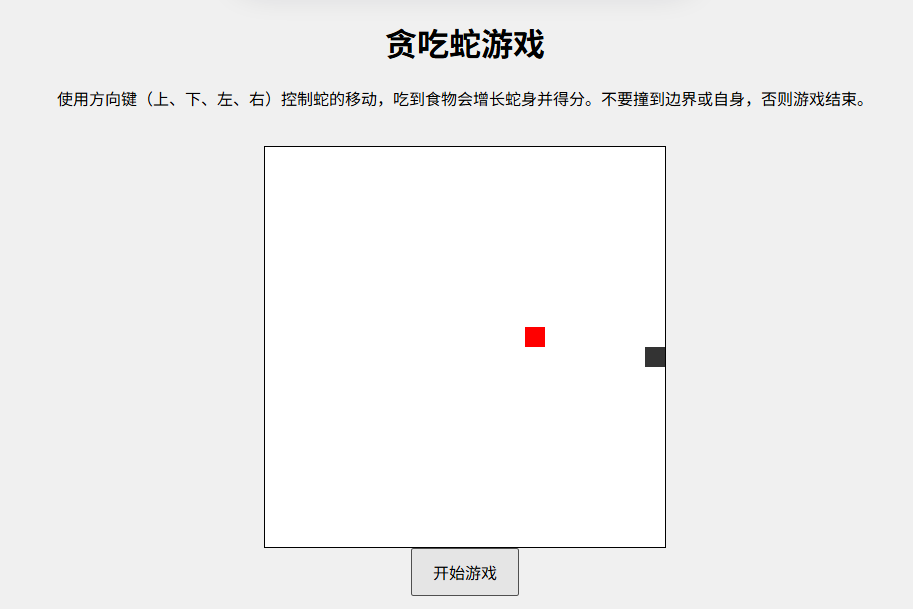
回答特点:
代码功能完整,包含食物生成和碰撞检测,结束游戏后也会有分数统计,界面简洁美观,整体表现优秀。
Claude 4 Sonnet:
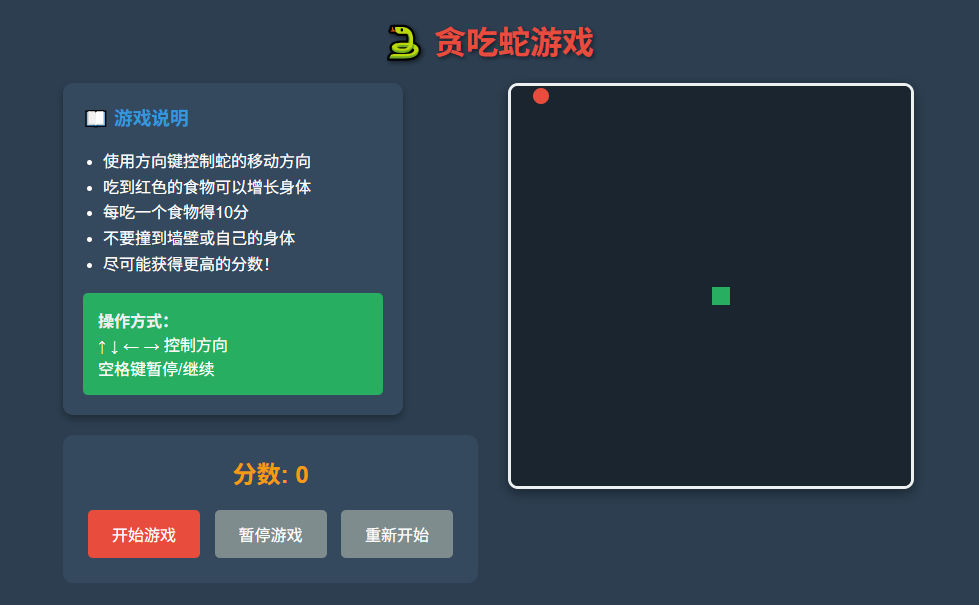
回答特点:
生成代码功能完整,界面设计精美,包含动画效果,但是运行还是有点问题,不能成功使用上下左右键去操作贪吃蛇,逻辑设置不够严谨,影响游戏体验。
分析:
Grok 3 的代码在功能性和趣味性上表现最佳,Gemini 2.5 Flash 次之,提供了稳定且美观的实现。Claude 4 Sonnet 虽在界面设计上用心,但逻辑瑕疵和运行问题降低了整体评分。
模型特性与应用场景
Gemini 2.5 Flash Preview (05-20)
- 特性:轻量级模型,优化速度和成本,token 消耗降低 20-30%,支持多模态处理。
- 优势:图像识别和交互任务表现优秀,成本低。
- 应用场景:客户服务、图像分析、快速内容生成。
- 局限性:复杂推理能力稍弱。
Grok 3 Reasoning
- 特性:xAI 的旗舰模型,支持 1M token 上下文窗口,配备 Think 和 Big Brain 模式,通过强化学习优化推理能力。Think 模式提供分步推理,Big Brain 模式分配额外计算资源处理复杂任务,DeepSearch 支持实时网络数据分析,Elo 评分为 1402(Chatbot Arena)。
- 优势:逻辑推理和代码生成能力强,推理过程透明,适合技术开发。
- 应用场景:复杂问题求解、软件开发、科学研究。
- 局限性:暂不支持直接图像处理。
Claude 4 Sonnet
- 特性:支持 200K token 上下文窗口,擅长代码生成和复杂推理,具备多模态能力。
- 优势:代码和文本分析能力强,推理稳定。
- 应用场景:软件开发、内容创作、复杂工作流管理。
- 局限性:视觉任务中易出现偏差。
综合评价与建议
- Gemini 2.5 Flash:适合预算有限的多模态任务,图像处理和交互能力突出。
- Grok 3 Reasoning:在逻辑推理和代码生成中表现最佳,适合需要深度推理的场景。
- Claude 4 Sonnet:推理和代码能力稳定,适合文本分析和开发任务。
开发者可通过 POLOAPI 的测试环境验证模型性能,选择适合的模型。
使用方式:
我们这里借助cherry studio进行对多个模型的调用,模型来源的API来自于POLOAPI。
具体接入方式如下:
(1)获取APIkey
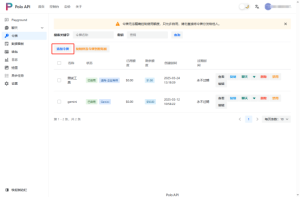
来到poloai.top的POLOAPI首页,点击API令牌,点击添加按钮,输入自定义名称,选择对应的令牌分组,添加成功后,点击复制按钮,即可得到APIkey
(2)接入大模型API
点击cherry studio设置,之后点击模型服务,点击下方图片显示的添加按钮;
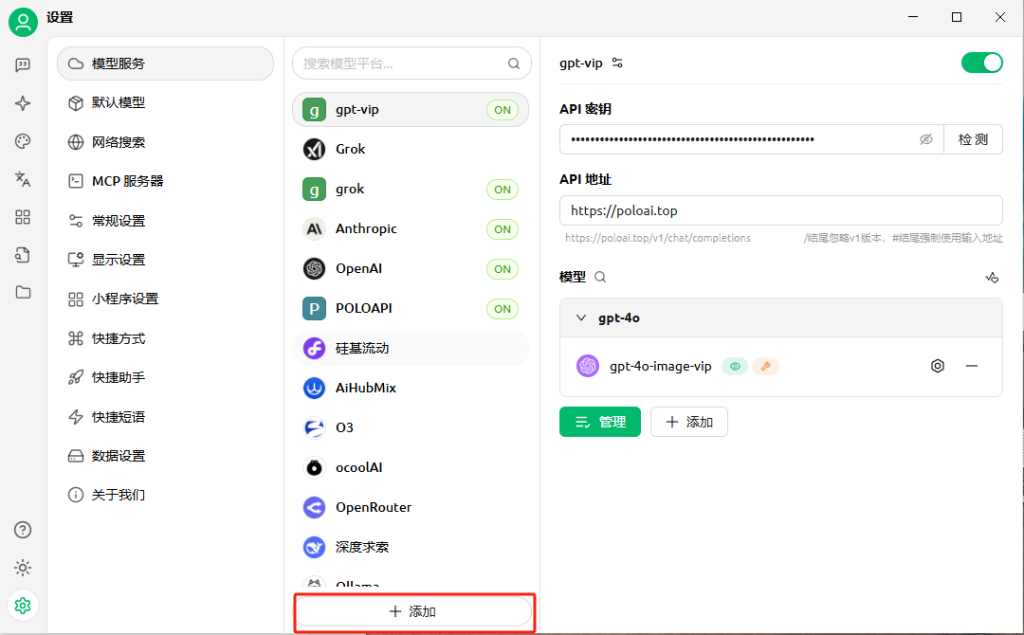
按照以下图片的提示进行填写信息,点击确认按钮;
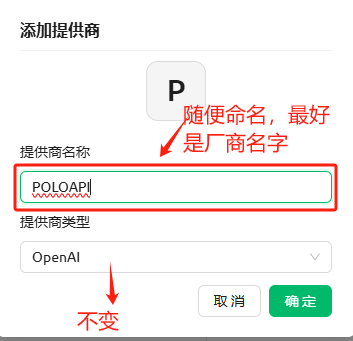
在API密钥那里填入从POLOAPI获得的APIkey,API地址如图填写,之后添加模型;
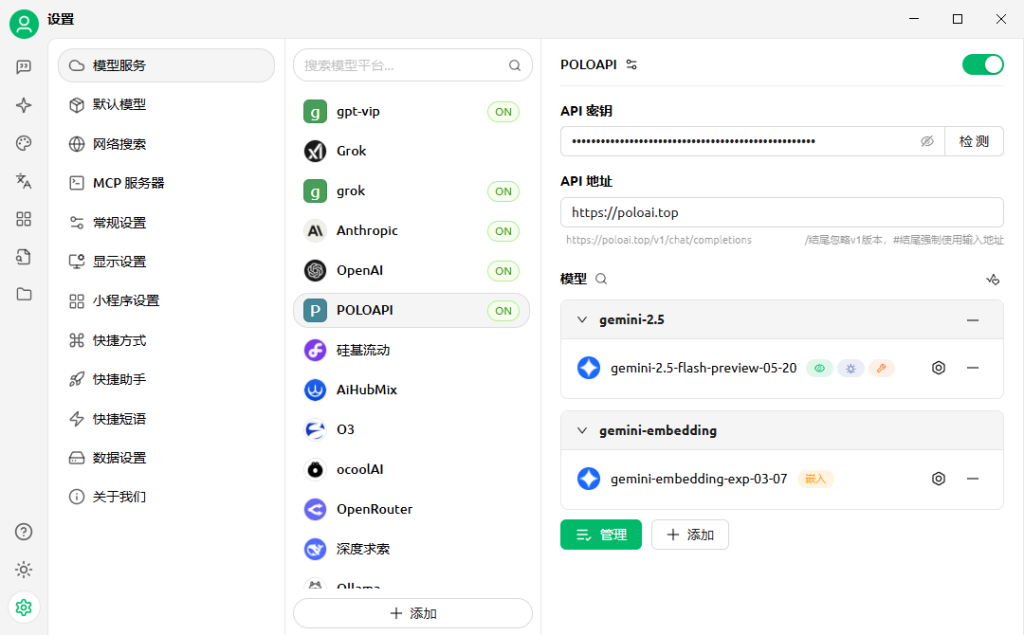
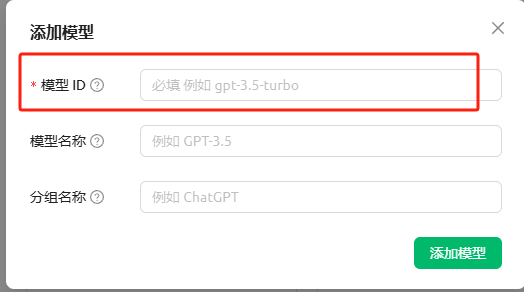
在POLOAPI的定价表里面选择APIkey对应的模型填入。我们这里以gemini-2.5-flash-preview-05-20为例
添加成功后会在模型下面显示:
之后点击检测按钮1,弹出“连接成功”,之后打开“开关按钮”,如下图的2;

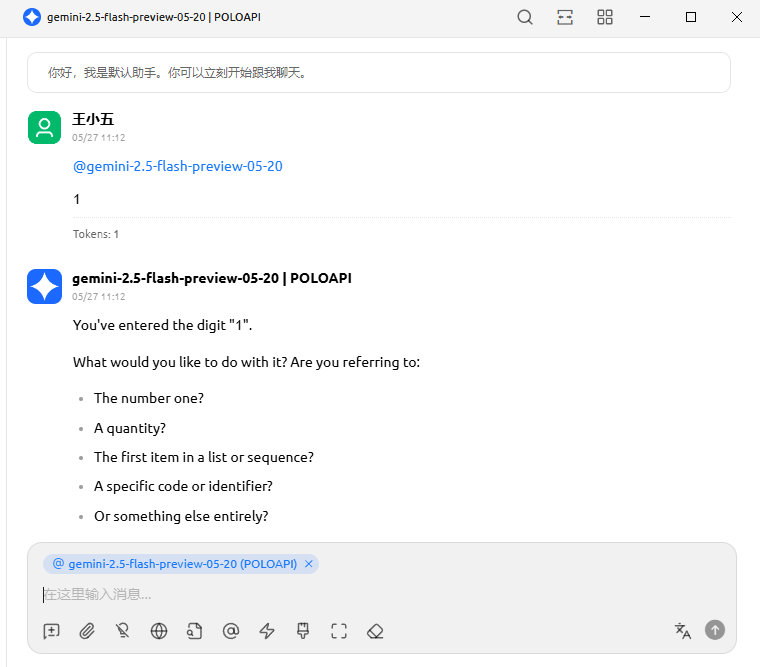
之后到主页测试回答,可以通过选择@这个模型进行进行测试,以下的情况则证明测试接入成功







暂无评论内容