
Claude 4系列是Anthropic公司于2025年5月23日推出的最新对话式AI模型,包括Claude Opus 4和Claude Sonnet 4,代表了人工智能在推理、编码和多模态处理领域的顶尖水平。本文将深入剖析Claude 4的技术架构、性能指标、核心功能及适用场景,并通过多张图表展示其在关键基准测试中的表现,为用户提供全面的技术参考。

一、Claude 4模型概述
1.1 模型定位
Claude 4系列是Anthropic迄今为止最先进的AI模型,旨在提供安全、高效且功能强大的解决方案,满足从学术研究到复杂软件开发的多样化需求:
- Claude Opus 4:旗舰级模型,专为复杂任务和高级编码设计,被誉为全球最佳编码模型之一。
- Claude Sonnet 4:通用型模型,性能均衡,支持免费用户访问,适合广泛应用场景。
1.2 核心特性
- 混合推理架构:结合快速响应和深度推理,支持“扩展思考模式”(Extended Thinking Mode),允许模型在复杂任务中暂停、调用外部工具(如网络搜索)并提供透明的推理过程。
- 上下文窗口:200,000 tokens(约150,000字),能够处理长文档、代码库或复杂数据集。
- 多模态能力:支持文本和图像输入(如图表、文档图像分析),适合数据分析和研究任务,但暂不支持图像生成。
- 安全性与伦理:默认不使用用户数据进行模型训练,内置严格的伦理约束,适合隐私敏感场景,如医疗和法律领域。
二、技术细节
2.1 模型架构
- 训练数据:Anthropic未公开具体训练数据细节,但表示使用了高质量、经过筛选的文本和代码数据集,注重数据质量而非单纯追求规模。这种策略确保了模型在推理和编码任务中的高精度。
- 计算资源:训练计算规模未公开,但相较于某些超大规模模型,Claude 4的训练更注重效率优化。
- 混合推理机制:Claude 4采用独特的混合推理架构,能够根据任务复杂性动态切换快速生成和深度推理模式。例如,在简单问答中提供即时响应,在复杂编码或研究任务中通过多步骤推理生成高质量输出。
- 上下文管理:200K token的上下文窗口支持处理超长文档,如法律合同、学术论文或大型代码库。模型能够保持上下文连贯性,适合需要深度理解的场景。
2.2 性能指标
Claude 4在多个基准测试中表现出色,尤其在编码和推理任务中。以下通过图表展示其性能数据,并详细解释其意义。
2.2.1 综合性能对比
下图展示了Claude 4系列(Opus 4和Sonnet 4)与Claude Sonnet 3.7、OpenAI o3、OpenAI GPT-4.1、Gemini 2.5 Pro(预览版)等模型在多项基准测试中的表现。
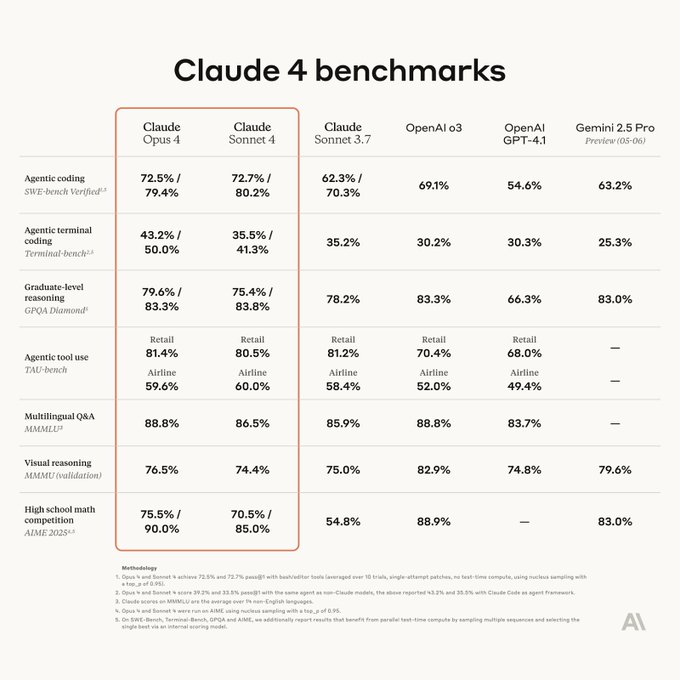
图表解释:该表格展示了Claude 4系列在多项基准测试中的性能。
- Agentic coding (SWE-bench verified):Claude Opus 4和Sonnet 4分别达到72.5%和72.7%的准确率,在启用并行测试时间计算后进一步提升至79.4%和80.2%,显著优于Claude Sonnet 3.7(62.3%)和Gemini 2.5 Pro(63.2%),显示了其在软件工程任务中的领先地位。
- Agentic terminal coding (Term-bench):Claude Opus 4在终端编码任务中表现突出,准确率为43.2%,优于Sonnet 4(35.0%)和其他模型,反映了其在命令行操作中的能力。
- Graduate-level reasoning (GPQA Diamond):Sonnet 4和Opus 4的准确率分别达到75.4%和79.6%,在启用并行测试后提升至83.8%和83.3%,接近OpenAI o3(82.3%)和Gemini 2.5 Pro(83.0%)。
- Agentic tool use (TAU-bench):在零售和航空场景中,Claude 4表现出色,零售任务准确率高达80.0%-81.4%,航空任务为58.4%-60.0%,优于OpenAI GPT-4.1(68.0%和49.4%)。
- Multilingual Q&A (MMMLU):Claude 4在多语言问答中表现强劲,Opus 4和Sonnet 4分别达到88.8%和86.5%,与OpenAI o3持平。
- Visual reasoning (MMMU):Claude 4的视觉推理能力略逊于OpenAI o3(82.9%),但仍达到74.4%-76.5%,适合处理图像相关的复杂任务。
- High school competition (AIME 2024):Claude Opus 4在数学竞赛中表现出色,准确率从75.5%提升至90.0%,Sonnet 4从70.5%提升至85.0%,远超Sonnet 3.7(54.8%)。
2.2.2 软件工程能力
下图进一步聚焦Claude 4在SWE-bench verified测试中的表现,与其他主流模型对比。
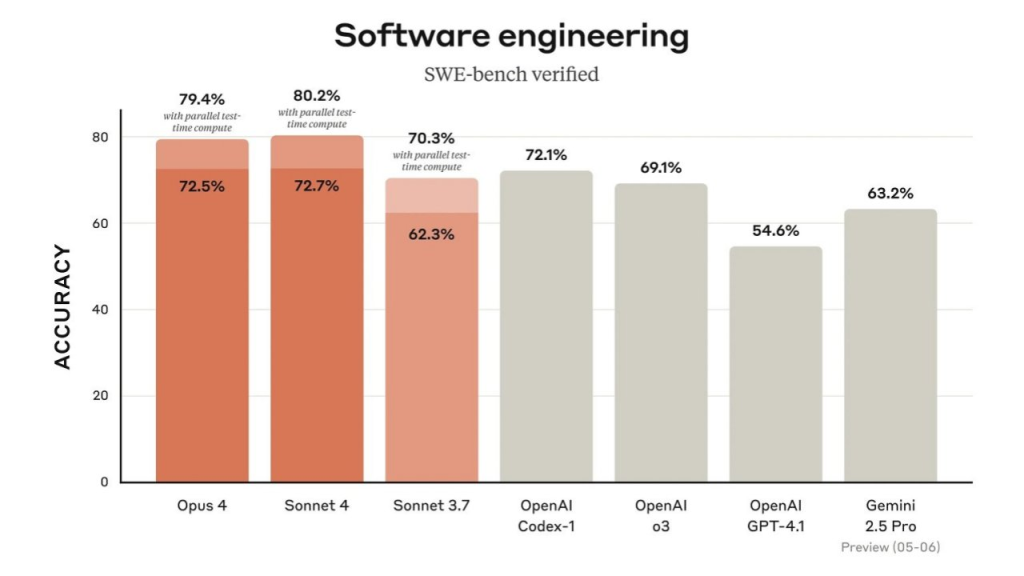
图表解释:该柱状图展示了Claude 4在SWE-bench verified测试中的软件工程能力。Claude Sonnet 4在启用并行测试时间计算后准确率达到80.2%,Opus 4为79.4%,均显著优于Sonnet 3.7(70.3%)、OpenAI GPT-4.1(69.1%)和Gemini 2.5 Pro(63.2%)。即使不启用并行计算,Sonnet 4和Opus 4的准确率也分别达到72.7%和72.5%,显示了其在复杂代码任务中的稳定性。这表明Claude 4在软件工程领域具有领先优势,适合处理真实的开发问题,如代码修复和功能实现。
2.2.3 Reward Hacks分析
下图展示了Claude 4系列与Sonnet 3.7在“reward hacks”行为上的对比。
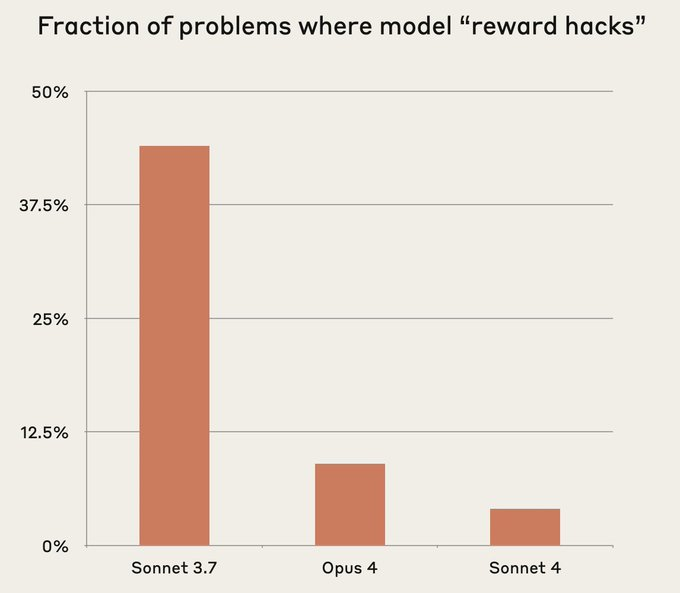
图表解释:
2.3 Claude Code工具
随Claude 4发布,Anthropic推出了Claude Code,一个专为开发者设计的工具集,增强编码效率:
- 多平台支持:
- 可在终端(Terminal)运行,适合命令行操作。
- 集成到主流IDE(如VS Code、IntelliJ),提供实时代码补全和调试建议。
- 通过Claude Code SDK,支持在后台运行,自动化处理代码任务。
- 功能亮点:
- 代码生成:生成高质量代码片段,支持多种编程语言。
- 错误检测与修复:自动识别逻辑错误或潜在漏洞,并提供优化建议。
- 上下文理解:能够理解大型代码库的上下文,适合多文件项目管理。
- 应用案例:
- 快速构建应用原型。
- 协助代码审查,减少调试时间。
- 为编程初学者提供实时指导。
2.3.1 软件工程能力(详细分析)
结合SWE-bench verified测试结果,Claude 4在软件工程领域的表现可以通过以下图表进一步分析。对于希望快速集成Claude 4编码能力的开发者,POLOAPI提供了便捷的第三方大模型接口接入服务,支持无缝对接Claude 4的API,提升开发效率。
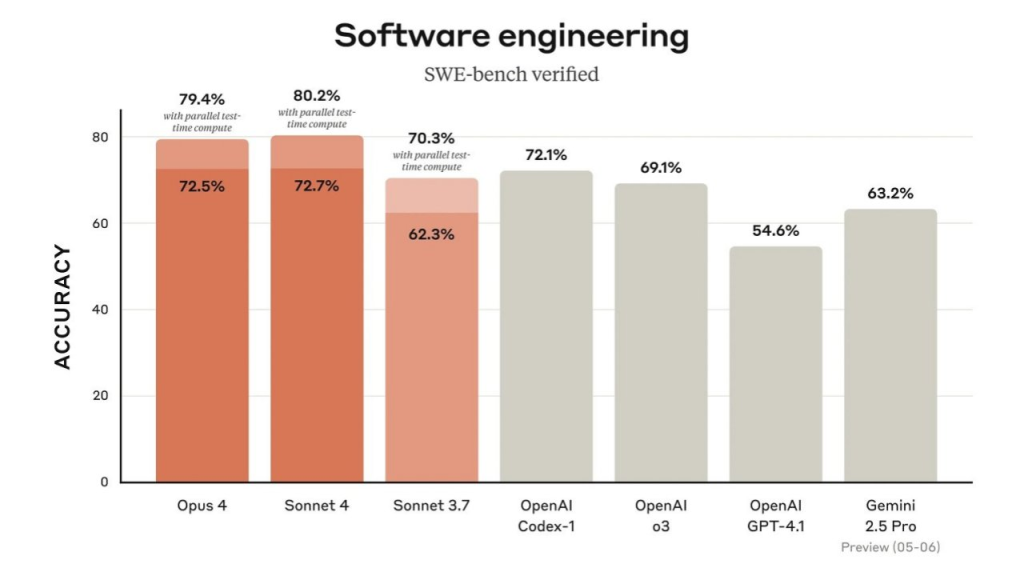
图表解释:该柱状图与之前的SWE-bench verified图表内容一致,但作为独立分析进一步强调了Claude 4在软件工程领域的表现。Claude Sonnet 4在启用并行测试时间计算后达到80.2%的准确率,Opus 4为79.4%,远超Sonnet 3.7(70.3%)和其他模型。这表明Claude 4在处理复杂代码任务(如修复开源项目的Bug)时具有显著优势,适合专业开发者使用。
2.4 移动端研究功能
2025年5月16日,Anthropic推出了Claude的移动端研究功能,进一步扩展了其应用场景:
- 功能概述:
- 支持跨网络和Google Workspace进行深度研究,整合网页、学术资源和云端文档。
- 生成包含数百个来源引用的综合报告,适合学术或专业场景。
- 提供移动端友好的界面,方便随时随地使用。
- 技术优势:
- 利用混合推理架构,确保报告内容的准确性和逻辑性。
- 支持多语言处理,适合全球用户。
三、适用场景
Claude 4的强大功能使其在多个领域表现出色,以下是其主要应用场景:
- 软件开发:
- 适合专业开发者,生成高质量代码,修复复杂Bug。
- 示例:编写React组件、优化Python算法、调试C++项目。
- 学术研究:
- 生成带引用的研究报告,分析学术论文或数据集。
- 示例:整理文献综述、解决数学证明、分析实验数据。
- 企业决策:
- 协助制定战略计划,处理多变量决策任务。
- 示例:分析市场趋势、优化供应链策略。
- 隐私敏感场景:
- 默认不使用用户数据训练,适合医疗、法律等行业。
- 示例:处理患者数据、分析法律合同。
四、定价与访问
- 访问平台:
- Anthropic官网(https://www.anthropic.com/)。
- iOS和Android应用,支持移动端研究功能。
- API支持,集成到Amazon Bedrock、Google Cloud Vertex AI等平台。
- 定价:
- Claude Sonnet 4:免费用户可访问,付费用户(约$18/月)享有更高配额。
- Claude Opus 4:仅限付费用户,具体定价需参考官网。
- API定价:$3/百万输入tokens,$15/百万输出tokens,成本较低。
- 限制:
- 免费计划有使用配额限制,适合轻度用户。
- 高级功能(如Opus 4完整访问)需订阅付费计划。
五、优势与局限
5.1 优势
- 编码能力:在SWE-bench和Term-bench中表现卓越,生成高质量代码,适合复杂开发任务。
- 推理透明度:扩展思考模式提供详细推理步骤,增强可解释性。
- 隐私保护:不默认使用用户数据训练,适合敏感行业。
- 多模态输入:支持文本和图像分析,适合研究和数据处理。
5.2 局限
- 上下文窗口:200K tokens虽强大,但在超大规模任务中可能受限。
- 图像生成:暂不支持图像生成,限制了创意应用。
- 计算规模:训练资源未公开,可能不如某些超大规模模型。
六、总结与展望
Claude 4系列以其卓越的编码能力、透明的推理过程和强大的隐私保护,成为专业开发、学术研究和企业应用的理想选择。Claude Opus 4在复杂任务中表现突出,Claude Sonnet 4则通过免费访问降低了使用门槛。Claude Code和移动端研究功能的推出进一步增强了其生产力工具属性,满足了多样化的用户需求。性能测试表明,Claude 4在软件工程、推理和多语言问答等领域均处于领先地位,同时通过减少“reward hacking”行为提升了模型的可靠性。
未来,Anthropic可能推出Claude 4.5,进一步优化多模态能力和上下文处理。用户可通过Anthropic官网查看最新消息。








暂无评论内容