
大规模AI模型(常称为“大模型”)正迅速成为人工智能领域的核心驱动力。这类模型拥有数十亿甚至上百亿的参数,能够胜任诸如自然语言生成、图像识别和智能推荐等高复杂度任务。本文将深入探讨大模型的定义、技术特征、典型应用及训练挑战,并辅以实用代码示例,为开发者、研究者和AI爱好者提供实战指南。
什么是大规模AI模型?
大规模AI模型是基于深度神经网络的学习系统,其特点是包含海量参数(通常为十亿级以上),通过大规模数据训练以实现高度抽象和泛化能力。与传统机器学习模型相比,大模型在模式识别、复杂推理和多模态任务中具有明显优势。
核心特性
-
海量参数:如 Grok 3 或 LLaMA 等现代大模型,参数规模可达数十亿,具备更强的学习能力。
-
极高计算需求:训练通常依赖多个 GPU 或 TPU 节点组成的集群,资源成本较高。
-
多模态支持:能够同时处理文本、图像、语音等多种数据类型,支持跨模态理解和生成。
应用场景与代码实战
1. 自然语言处理(NLP)
大模型广泛应用于文本生成、自动摘要、翻译和对话系统。以下是一个使用 BART 模型进行文本摘要的示例:
from transformers import BartForConditionalGeneration, BartTokenizer
import torch
# 加载 BART 模型和分词器
model_name = "facebook/bart-base"
tokenizer = BartTokenizer.from_pretrained(model_name)
model = BartForConditionalGeneration.from_pretrained(model_name).to("cuda" if torch.cuda.is_available() else "cpu")
# 输入文本
text = "人工智能通过自动化和数据分析,正在改变医疗、教育和交通等领域。"
inputs = tokenizer(text, return_tensors="pt", max_length=512, truncation=True).to(model.device)
# 生成摘要
summary_ids = model.generate(inputs["input_ids"], max_length=30, num_beams=4)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print("摘要:", summary)输出示例:人工智能通过自动驾驶和智能助手等技术改变生活方式。
2. 计算机视觉
在图像分类、目标检测和图像生成等任务中,大模型同样表现卓越。以下代码展示了使用 ResNet18 进行图像分类的过程:
import torch
from torchvision.models import resnet18, ResNet18_Weights
import torchvision.transforms as transforms
from PIL import Image
# 确定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载预训练模型
model = resnet18(weights=ResNet18_Weights.DEFAULT).eval().to(device)
# 获取模型预处理转换方式
transform = ResNet18_Weights.DEFAULT.transforms()
# 加载图像
image = Image.open("C:\\Users\\Administrator\\PyCharmMiscProject\\picture\\images.jpg")
input_tensor = transform(image).unsqueeze(0).to(device)
# 执行预测
with torch.no_grad():
output = model(input_tensor)
predicted_class = torch.argmax(output, dim=1).item()
print("预测类别ID:", predicted_class)3. 推荐系统
在个性化内容推荐方面,大模型通过建模用户偏好来提升服务质量。以下为基于简单 MLP 的推荐模型示例:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
# 定义推荐模型
class Recommender(nn.Module):
def __init__(self):
super(Recommender, self).__init__()
self.network = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
def forward(self, x):
return self.network(x.view(-1, 784))
# 加载 MNIST 数据集
dataset = MNIST(root='.', train=True, download=True, transform=transforms.ToTensor())
loader = DataLoader(dataset, batch_size=64, shuffle=True)
# 训练模型
model = Recommender()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(5):
total_loss = 0
for images, labels in loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(loader)
print(f"Epoch {epoch + 1}, Average Loss: {avg_loss:.4f}")训练挑战与技术应对
尽管大模型功能强大,其训练过程却面临以下挑战:
-
资源密集型:训练需要庞大的计算资源与显存。
-
数据处理复杂:高质量大规模数据的收集、清洗与标注成本高昂。
-
优化难度高:大模型参数众多,训练容易陷入局部最优或不稳定状态。
-
部署代价大:模型文件庞大,推理速度慢,部署成本高。
应对策略:分布式训练
分布式训练是解决资源瓶颈和加速训练的重要技术。以下是基于 PyTorch 的分布式数据并行(DDP)训练示例:
import os
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset, DistributedSampler
# 设置通信环境变量
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12345'
os.environ['RANK'] = '0'
os.environ['WORLD_SIZE'] = '1'
# 初始化分布式训练
dist.init_process_group(backend='gloo')
rank = dist.get_rank()
world_size = dist.get_world_size()
# 指定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 自定义简单数据集
class RandomDataset(Dataset):
def __len__(self):
return 100
def __getitem__(self, idx):
x = torch.randn(10)
y = torch.randint(0, 5, (1,)).item()
return x, y
# 构建数据加载器
dataset = RandomDataset()
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=True)
dataloader = DataLoader(dataset, batch_size=32, sampler=sampler, num_workers=0)
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# 包装为分布式模型
model = SimpleModel().to(device)
model = DDP(model, device_ids=[rank] if torch.cuda.is_available() else None)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# 执行训练循环
for epoch in range(5):
dataloader.sampler.set_epoch(epoch)
for data, target in dataloader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1} completed on rank {rank}")
# 清理通信资源
dist.destroy_process_group()📦模型压缩与部署优化
由于大模型在参数规模和计算量方面远超传统模型,其部署往往面临推理速度慢、显存需求高等问题。为此,模型压缩技术成为关键解决方案。
常用压缩技术
-
量化(Quantization):将浮点参数压缩为低比特精度(如 INT8),显著减少模型大小和推理时间。
-
剪枝(Pruning):移除冗余参数连接,减少计算量和内存占用。
-
蒸馏(Knowledge Distillation):使用大模型(教师)指导小模型(学生)训练,实现性能传递。
例如使用 torch.quantization 模块可对模型进行动态量化(简略代码):
import torch.quantization
# 对模型执行动态量化(以线性层为例)
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)这种方式适用于部署前优化推理效率,尤其适合资源受限的边缘设备或移动端应用。
🌐多模态大模型:跨模态智能的未来
随着 AI 任务复杂度不断提升,单一模态模型已难以满足需求。多模态大模型可同时处理文本、图像、音频等多种数据类型,实现更丰富的理解与生成能力。
应用代表
-
CLIP(OpenAI):将图像和文本投影到同一语义空间,实现图文检索与理解。
-
Flamingo(DeepMind):支持图像-文本混合输入的问答与生成。
-
Grok-Vision:集成视觉和语言能力,支持图像描述、文图问答等任务。
这种模型正推动 AI 向更强的通用智能迈进。以下是典型应用场景:
-
图文内容生成(电商、社交平台)
-
多模态检索(医疗影像+文本病例)
-
智能问答(图像+语言输入)
🔌第三方大模型API接入:快速上手,灵活扩展
对于开发者而言,训练和部署完整的大模型成本高昂,而通过调用第三方 API 即可轻松使用先进能力。这里推荐一个支持多家主流模型的中文聚合平台 —— POLOAPI。
💡 POLOAPI:一个面向开发者的多模型智能接口平台
集成 GPT-4、Claude、ERNIE、百川、通义千问、讯飞星火等数十种模型
提供统一 RESTful 接口,支持上下文连续、多轮对话、图文混输等复杂任务
提供免费试用额度与 Key 管理控制台
适用于对接聊天机器人、问答系统、内容生成、智能搜索等业务
例如使用 POLOAPI 接口发送文本生成请求:
import requests
API_KEY = "sk-xxx" #复制的令牌填写进去
# 修正后的URL(假设使用/v1/chat/completions路径)
url = "https://poloai.top/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": "claude-3-5-haiku-20241022",
"messages": [
{"role": "user", "content": "请简要总结大规模AI模型的训练难点和优化策略。"}
],
"temperature": 0.7,
"max_tokens": 300
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
# 根据实际返回格式调整
reply = result.get("choices", [{}])[0].get("message", {}).get("content", "")
print("模型回复:\n", reply)
else:
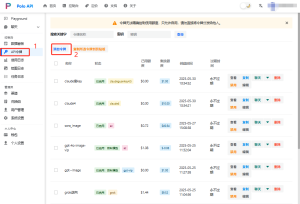
print(f"请求失败,状态码:{response.status_code}\n响应内容:{response.text}")这里的令牌获取,进入第三方大模型API集成平台POLOAPI,点击API令牌,点击添加令牌,填写自定义名称(最好填写模型名称之类的,方便更快的分辨清楚),选择对应的分组,提交,点击刚才提交成功的信息条对应的“复制”按钮,之后把这里得到的令牌填写到上面的API_KEY上,之后对其进行测试,比如,运行以上代码,得到回复则证明接入成功。如图下所示:

你可以根据不同模型选择对应接口路径,参数设置也非常灵活。
通过 POLOAPI,开发者无需部署大模型,即可快速构建各类 AI 应用,极大降低研发门槛,特别适合小型团队或原型项目开发。
✅ 总结
大规模AI模型推动了人工智能从“窄智能”走向“通用智能”。通过掌握其训练流程、优化技巧与应用接口,开发者可快速构建强大的AI系统,满足从科研到产品的多种需求。









暂无评论内容