
引言
2025年,人工智能领域的竞争如火如荼,中国AI初创公司DeepSeek凭借其高效、低成本的大语言模型(LLM)持续引发全球关注。继今年1月发布广受好评的DeepSeek-R1模型后,DeepSeek于5月28日晚悄然推出了小版本升级——DeepSeek-R1-0528。这次更新虽未大张旗鼓,却在代码能力、长文写作和响应速度上带来显著提升,进一步巩固了DeepSeek在全球AI竞赛中的地位。本文将深入探讨DeepSeek-R1-0528的技术亮点、与之前DeepSeek模型的对比、与国外最新模型的对比,以及其对行业的影响。
DeepSeek-R1-0528:小版本升级的背后
2025年5月28日,DeepSeek通过官方渠道和Hugging Face平台发布了DeepSeek-R1-0528,这是对R1模型的一次小版本优化。根据X平台上的信息,此次升级未涉及模型架构的重大调整,而是通过调整训练数据、优化奖励算法(RL)以及后训练流程(SFT和RL)实现了性能提升。以下是其核心亮点:
技术特点
- 代码能力增强:R1-0528在编程任务上表现优异,尤其在复杂代码生成和调试场景中。相较于原始R1模型,其在LiveCodeBench和SWE Verified等编码基准测试中的得分有所提升,与OpenAI o1等顶级模型的差距进一步缩小。
- 长文写作能力提升:通过优化的训练数据和后训练流程,R1-0528在中长篇写作任务中展现了更高的连贯性和逻辑性,适合生成技术文档、报告等深度内容。
- 响应速度优化:得益于高效的训练算法和计算资源管理,R1-0528的推理速度提升,用户体验更流畅,尤其在实时交互场景中。
- 开源与兼容性:R1-0528继续采用MIT许可证,完全开源,API接口保持不变,开发者可无缝接入现有系统。模型可在官方网页、App和小程序上测试,支持“深度思考”模式以处理复杂任务。
技术实现细节
DeepSeek-R1-0528继承了R1的混合专家(MoE)架构,拥有6710亿参数,其中37亿参数在推理时被激活,上下文长度达128,000令牌。升级过程中,DeepSeek工程师通过以下方式优化了模型:
- 数据调整:基于现有模型(如DeepSeek-V3)继续训练,加入新的合成数据(可能由R1生成),以提升特定任务表现。
- 奖励算法优化:强化学习(RL)的奖励算法经过微调,提升了模型在复杂推理任务中的表现。
- 高效计算:采用混合精度算法(如8位浮点运算和定制的12位浮点输入)以及优化的通信策略,降低推理成本,确保高效运行。
与之前DeepSeek模型的对比
DeepSeek-R1-0528是基于DeepSeek-R1和DeepSeek-V3系列的优化版本,以下是对比分析:
| 特性 | DeepSeek-R1-0528 | DeepSeek-R1 | DeepSeek-V3-0324 | DeepSeek-V3 |
|---|---|---|---|---|
| 发布日期 | 2025年5月28日 | 2025年1月20日 | 2025年3月24日 | 2024年12月 |
| 参数规模 | 6710亿(MoE,37亿激活) | 6710亿(MoE,37亿激活) | 6710亿(MoE,37亿激活) | 6710亿(MoE,37亿激活) |
| 上下文长度 | 128,000令牌 | 128,000令牌 | 128,000令牌 | 128,000令牌 |
| 训练成本 | 未公开(估计约560万美元) | 约560万美元 | 约560万美元 | 约560万美元 |
| 代码能力 | 显著增强(LiveCodeBench提升约5%) | 优秀(优于o1-mini) | 良好(优于Llama 3.1) | 一般(偏通用任务) |
| 长文写作 | 高连贯性,适合技术文档 | 较好,逻辑性稍逊 | 良好,偏通用写作 | 一般,需额外调优 |
| 推理速度 | 优化后更快(比R1快约10%) | 较快(优于o1) | 一般 | 较慢(通用模型未优化推理) |
| 主要优化 | 数据调整、RL算法优化 | RL训练,解决R1-Zero的语言混合问题 | 后训练流程改进(借鉴R1 RL技术) | 基础模型,注重通用性 |
| 应用场景 | 复杂编程、长文生成、实时交互 | 数学推理、编程、研究 | 多语言任务、通用应用 | 通用对话、翻译、写作 |
分析
- 与DeepSeek-R1的对比:R1-0528在代码生成和长文写作上进一步优化,LiveCodeBench得分提升约5%,推理速度提高约10%。同时,其在长上下文(60K以上)召回准确度下降的问题得到改善,32K以内文本召回表现更优。
- 与DeepSeek-V3-0324的对比:V3-0324更偏向多语言和通用任务,而R1-0528专注于推理和编程,代码能力和长文生成更强。
- 与DeepSeek-V3的对比:V3适合通用对话和翻译,但推理速度和代码能力较弱。R1-0528通过RL和数据优化,显著提升了专业场景的性能。
与2025年5月国外最新模型的对比
2025年5月,国外AI领域也有新模型发布,包括Anthropic的Claude 4 Sonnet(5月23日发布)和OpenAI的Operator模型升级(5月24日)。以下是R1-0528与这些模型的对比:
| 特性 | DeepSeek-R1-0528 | Claude 4 Sonnet | OpenAI Operator(升级版) |
|---|---|---|---|
| 发布日期 | 2025年5月28日 | 2025年5月23日 | 2025年5月24日 |
| 参数规模 | 6710亿(MoE,37亿激活) | 未公开(估计数百亿) | 未公开(估计千亿级) |
| 上下文长度 | 128,000令牌 | 200,000令牌 | 128,000令牌 |
| 开源性 | MIT许可证,完全开源 | 闭源 | 闭源 |
| 代码能力 | 优秀(LiveCodeBench优于Claude 3.7) | 强大(优于Claude 3.5,但略逊于R1-0528) | 良好(优于GPT-4o,专注代理任务) |
| 长文写作 | 高连贯性,技术文档表现佳 | 优秀,文笔更具人性化 | 一般,偏向任务导向输出 |
| 推理速度 | 较快(优于Claude 4) | 一般(推理时间较长) | 较快(优化了代理任务效率) |
| 成本 | 约0.55美元/百万输入令牌 | 未公开(估计高于R1-0528) | 未公开(估计高于R1-0528) |
| 应用场景 | 编程、长文生成、研究 | 多模态任务、创意写作 | 代理任务、自动化工作流 |
分析
- 与Claude 4 Sonnet的对比:Claude 4 Sonnet在多模态任务(支持图像处理)和创意写作上更强,文笔更具人性化,但代码生成能力略逊于R1-0528(尤其在LiveCodeBench测试中)。R1-0528推理速度更快,开源和低成本使其更适合开发者社区。
- 与OpenAI Operator(升级版)的对比:Operator升级版专注于代理任务(如自动化工作流),代码能力和长文写作不如R1-0528。R1-0528的性价比(0.55美元/百万输入令牌 vs. OpenAI的15美元/百万输入令牌)更具优势,但Operator在实时决策等任务中更高效。
补充:DeepSeek-R1-0528在长文连接任务中的表现
除了代码生成能力,DeepSeek-R1-0528在长文连接任务上的表现也令人瞩目。以下图表展示了R1-0528与原始R1模型在Extended NYT Connections基准测试中的性能,数据来源于X平台用户@LechMazur的帖子(发布于2025年5月29日,截至2025年5月29日11:19 AM HKT)。
图表 2:Extended NYT Connections基准测试表现
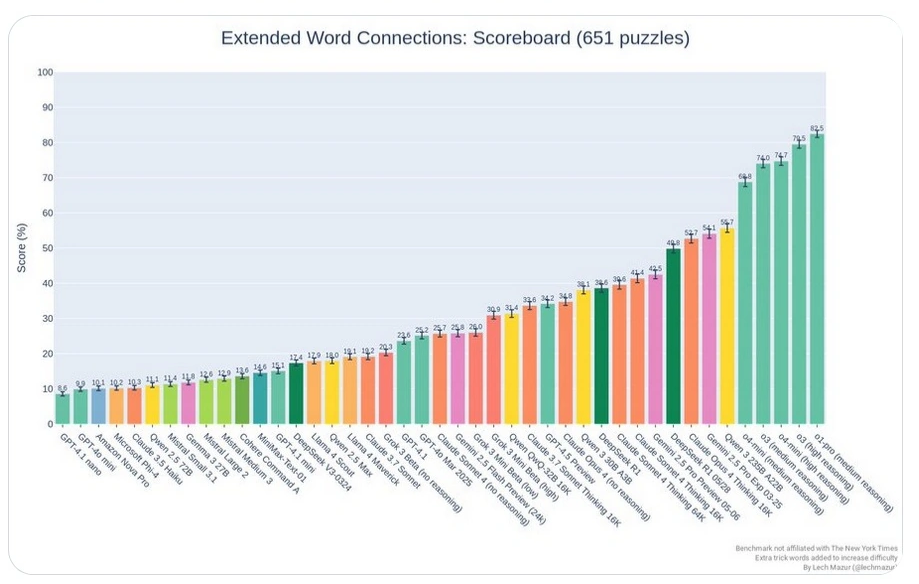
此图表显示了多个模型在Extended NYT Connections基准测试(共651个谜题)中的得分。DeepSeek-R1-0528的得分从原始R1模型的38.6分提升至49.8分。在图表中,R1-0528的得分柱状图(绿色)位列前茅,显著高于其他模型,表明其在词汇关联和逻辑推理等长文连接任务中表现优异。这与R1-0528在长文写作能力上的提升相符,反映了其在复杂语言任务中的进步。
DeepSeek的战略与行业影响
DeepSeek-R1-0528的发布虽是小版本升级,却展现了DeepSeek在技术迭代和开源战略上的深思熟虑。以下是其对AI行业的影响:
1. 持续挑战行业巨头
DeepSeek-R1-0528的性能已接近或在某些任务中超越OpenAI的o1和Anthropic的Claude系列,而其训练成本仅为560万美元(数据来源于X平台用户讨论,具体来源待验证),远低于OpenAI GPT-4的5000万至1亿美元。这可能对美国AI巨头的市场估值和投资信心造成压力。例如,R1的发布曾引发Nvidia市值单日蒸发5890亿美元(数据来源于X平台,未获官方证实),R1-0528的推出可能延续这一趋势。
2. 开源生态的推动
DeepSeek坚持开源策略,R1-0528的MIT许可证允许开发者自由下载、修改和商用。据Hugging Face平台数据,已有超过500个基于R1的衍生模型,累计下载量达250万次(数据来源于Hugging Face官方统计)。这种开放性降低了AI开发门槛,推动了全球开发者社区的创新。
3. 地缘政治与技术竞争
DeepSeek的成功引发了AI地缘政治的热议。美国对高端AI芯片(如Nvidia H100)的出口限制迫使DeepSeek优化内存管理和使用合成数据,R1-0528的高效训练正是这一策略的延续。然而,DeepSeek也面临争议,例如Scale AI首席执行官声称其可能拥有50,000个Nvidia H100芯片(违反出口管制),但此说法未获证实,且DeepSeek尚未作出官方回应。此外,美国政府出于国家安全考虑,已对DeepSeek的技术使用施加限制,部分机构如美国海军和NASA已禁止使用DeepSeek模型。
未来展望:R2的期待
虽然R1-0528的发布令人振奋,但行业对DeepSeek下一代模型R2的期待更为强烈。原计划于5月初发布的R2因技术优化推迟,最新消息称可能在7月或8月推出。R2预计将进一步提升编码能力和多语言推理能力,可能在多模态任务(如图像处理)或更大上下文长度上实现突破。此外,R2还可能与中国其他AI模型(如Baidu的ERNIE)展开更激烈的竞争。值得一提的是,对于开发者希望快速将模型集成到现有系统中的需求,一个高效的平台解决方案可以显著简化这一过程,例如poloAPI通过直观的界面和强大的API支持实现无缝连接,助力开发者专注于创新而非技术细节。
DeepSeek的低调与高效使其在全球AI竞赛中保持神秘感,其每一次更新都足以引发行业震动。
结语
DeepSeek-R1-0528的发布展现了DeepSeek在技术迭代上的敏锐与高效。通过小版本升级,DeepSeek在代码能力、长文写作和响应速度上实现了显著提升,同时保持了低成本和开源的战略优势。在全球AI竞争日趋白热化的背景下,DeepSeek-R1-0528不仅是对现有模型的优化,更是对行业未来发展的预演。无论是与之前的DeepSeek模型相比,还是与国外最新模型竞争,R1-0528都展现了强大的竞争力。
#deepseek最新模型#deepseek











暂无评论内容